Extracción de Información y Conciliación de Documentos Financieros mediante LLM
Plataforma: Ubuntu 20 Tipo: Proyecto Cerrado Fecha: 2023 - 2024 Enlace: No disponible
Resumen
Este proyecto tuvo como objetivo automatizar la extracción y conciliación de información financiera utilizando modelos de lenguaje (LLM) ejecutados completamente dentro de la infraestructura del cliente.
La solución fue diseñada para procesar documentos financieros semiestructurados, extraer información relevante, comparar los datos obtenidos con información reportada en correos electrónicos y generar reportes de conciliación para uso interno.
A diferencia de proyectos documentales anteriores, esta iniciativa exploró el uso de modelos de lenguaje para comprender documentos completos, permitiendo reducir la dependencia de layouts específicos y reglas de postprocesamiento.
Referencias Visuales
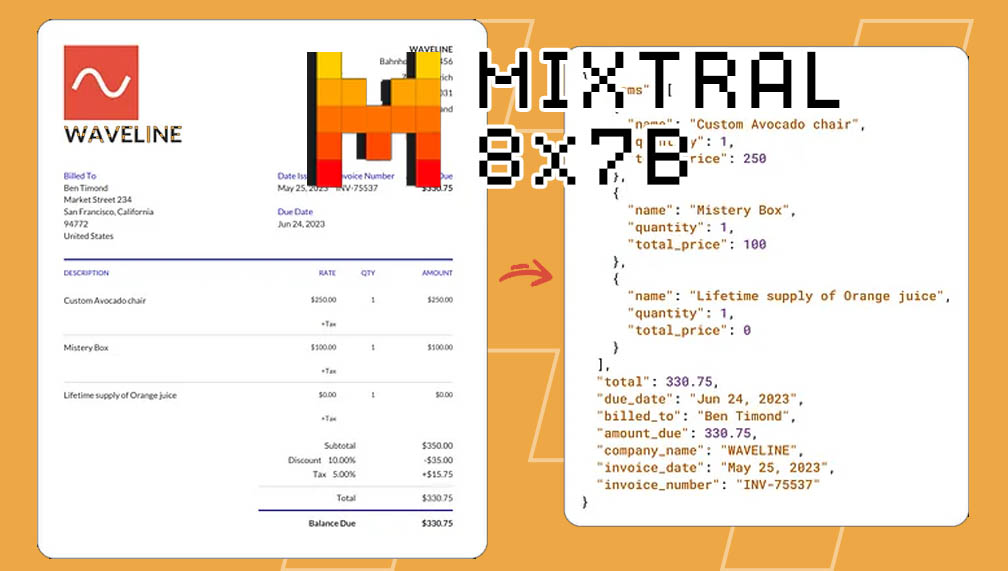
La siguiente imagen ilustra conceptualmente el proceso de transformación de documentos financieros en datos estructurados.
Contexto
Durante los años 2023 y 2024 los modelos de lenguaje comenzaron a demostrar capacidades prometedoras para la comprensión documental.
Sin embargo, existían dos desafíos importantes:
- Los modelos comerciales aún presentaban limitaciones de precisión y consistencia.
- Los documentos financieros procesados no podían abandonar la infraestructura interna del cliente.
Por esta razón se optó por una arquitectura basada en modelos open source ejecutados completamente dentro de la intranet.
Tras distintas evaluaciones se seleccionó Mixtral-7B como base de la solución.
Problema
El cliente necesitaba automatizar la extracción de información financiera desde documentos provenientes de múltiples fuentes.
La solución debía ser capaz de:
- Procesar documentos financieros semiestructurados.
- Comprender información distribuida en distintas secciones.
- Extraer tablas.
- Analizar información proveniente de correos electrónicos.
- Realizar conciliaciones automáticas.
- Detectar discrepancias.
- Generar reportes utilizables por equipos internos.
Además, toda la información debía permanecer dentro de la infraestructura corporativa.
Arquitectura General
Solución
La solución combinó procesamiento documental tradicional con modelos de lenguaje ejecutados localmente.
El flujo general consistía en:
- Recepción del documento.
- Conversión a texto estructurado.
- Procesamiento mediante Mixtral-7B.
- Extracción de campos financieros.
- Procesamiento de correos electrónicos asociados.
- Extracción de tablas.
- Conciliación de información.
- Generación de reportes.
El uso de un LLM permitió abordar documentos que anteriormente habrían requerido layouts específicos o reglas particulares para cada formato.
Extracción de Información Financiera
El modelo fue entrenado y ajustado para identificar información relevante presente en documentos financieros.
Entre los campos procesados se encontraban:
- Identificadores documentales.
- Fechas.
- Montos.
- Proveedores.
- Clientes.
- Valores asociados a líneas de detalle.
- Información contenida en tablas.
La meta del proyecto era alcanzar una precisión superior al 90% en los datos extraídos.
Conciliación Automática
Uno de los componentes más relevantes del proyecto fue la conciliación automática.
La información obtenida desde documentos era comparada con información reportada por correo electrónico.
Esto permitía identificar:
- Diferencias de montos.
- Registros faltantes.
- Fechas inconsistentes.
- Documentos no reportados.
- Posibles errores operacionales.
Seguridad y Confidencialidad
La confidencialidad fue uno de los factores más importantes en la definición de la arquitectura.
Por esta razón se descartó el uso de servicios externos y se optó por ejecutar el modelo completamente dentro de la infraestructura del cliente.
Esto permitía garantizar que:
- Los documentos no abandonaran la intranet.
- No existiera exposición de información sensible.
- Se cumplieran los requisitos internos de seguridad.
Mi Participación
Participé como líder técnico del proyecto.
Mis responsabilidades incluyeron:
- Diseño de la arquitectura.
- Evaluación de modelos disponibles.
- Selección de tecnologías.
- Coordinación del equipo.
- Definición de métricas.
- Supervisión de pruebas.
- Presentación de resultados.
- Diseño del sistema de conciliación.
También participé en la validación de distintas estrategias para maximizar precisión bajo restricciones de infraestructura.
Desafíos Técnicos
LLMs en una Etapa Temprana
Durante el desarrollo los modelos de lenguaje aún estaban evolucionando rápidamente.
Las capacidades disponibles eran significativamente menores que las existentes actualmente.
Restricciones de Infraestructura
El proyecto debía ejecutarse sin depender de hardware especializado de alto costo.
Esto obligó a seleccionar modelos que ofrecieran un equilibrio entre:
- Precisión.
- Velocidad.
- Consumo de recursos.
- Costos operacionales.
Consistencia de Resultados
Uno de los principales desafíos fue garantizar que las respuestas del modelo mantuvieran un formato consistente para facilitar la conciliación posterior.
Tecnologías Utilizadas
- Python
- Mixtral 7B
- OCR
- Procesamiento Documental
- Procesamiento de Correos Electrónicos
- Generación de Reportes Excel
- Ubuntu 20
- AWS
- Docker
Resultados
La solución permitió:
- Automatizar extracción documental.
- Procesar documentos financieros complejos.
- Extraer tablas automáticamente.
- Comparar información proveniente de distintas fuentes.
- Detectar discrepancias.
- Generar reportes consolidados.
- Mantener la información dentro de la infraestructura corporativa.
Lo que Aprendí
Este proyecto marcó una transición importante entre las soluciones tradicionales de procesamiento documental y los sistemas basados en modelos de lenguaje.
Los proyectos anteriores se apoyaban principalmente en:
- OCR.
- Layout Parsing.
- Reglas.
- Postprocesamiento.
La incorporación de un LLM permitió delegar parte de la comprensión documental al modelo, reduciendo la dependencia de estructuras rígidas.
También reforzó una lección importante: la capacidad de comprender documentos y la capacidad de extraer texto son problemas diferentes.
Mientras el OCR permite leer información, los modelos de lenguaje aportan contexto e interpretación.
Viéndolo en Retrospectiva
Mirando el proyecto años después, considero que fue una de mis primeras experiencias aplicando modelos de lenguaje a problemas documentales reales.
Aunque los LLM de aquella época estaban lejos de las capacidades actuales, la experiencia permitió anticipar una tendencia que posteriormente se volvería dominante en la industria: utilizar modelos de lenguaje para transformar documentos complejos en información estructurada.
Muchas de las decisiones técnicas tomadas durante este proyecto terminaron influyendo en iniciativas posteriores relacionadas con extracción documental avanzada, conciliación y automatización basada en inteligencia artificial.
Información Adicional
Por razones de confidencialidad no se incluyen documentos reales ni información financiera procesada durante el proyecto.
La imagen utilizada corresponde a una representación conceptual del proceso de extracción documental mediante modelos de lenguaje y se incluye únicamente con fines ilustrativos.